In 2014, I was the first to reveal previously-unknown Google contracts that required Android phone manufacturers and carriers to preload key Google apps, make them prominent, and in some instances not install competing apps. In 2018, the European Commission ruled this unlawful and imposed a €4.1 billion fine, and today the European Court of Justice upheld the finding and fine, and rejected the appeal.
The wheels of justice turn slowly. A ten digit fine is large, yet small relative to the benefit Google obtained by making its apps dominant in their respective fields — and demolishing competitors (or discouraging potential competitors from even trying). And justice delayed, by 12+ years since I first reported the problem, is in an important sense justice denied.
But there’s an even bigger problem lurking. Prior to me revealing the MADA contracts that embodied Google’s anticompetitive rules, Google leaders repeatedly claimed no such rules exist. Quoting from my 2014 article:
Andy Rubin, then Senior Vice President of Mobile at Google, in 2011 claimed that “[D]evice makers are free to modify Android to customize any range of features for Android devices.” He continued: “If someone wishes to market a device as Android-compatible or include Google applications on the device, we do require the device to conform with some basic compatibility requirements [hyperlink in the original]. (After all, it would not be realistic to expect Google applications—or any applications for that matter—to operate flawlessly across incompatible devices).” Rubin’s post does not explicitly indicate that the referenced “basic compatibility requirements” are the only requirements Google imposes, but that’s the natural interpretation. Reading Rubin’s remarks, particularly in light of his introduction that Android is “an open platform,” most readers would conclude that there are no significant restrictions on app installation or search defaults.
Google Chairman Eric Schmidt offered particularly far-reaching remarks on Google’s rules about mobile apps and search defaults. After a 2011 Senate hearing about competition in online search, Senator Kohl asked Schmidt (question 8.a):
Has Google demanded that smartphone manufacturers make Google the default search engine as a condition of using the Android operating system?
Google does not demand that smartphone manufacturers make Google the default search engine as a condition of using the Android operating system. …
One of the greatest benefits of Android is that it fosters competition at every level of the mobile market—including among application developers. Google respects the freedom of manufacturers to choose which applications should be pre-loaded on Android devices. Google does not condition access to or use of Android on pre-installation of any Google applications or on making Google the default search engine. …
Manufacturers can choose to pre-install Google applications on Android devices, but they can also choose to pre-install competing search applications like Yahoo! and Microsoft’s Bing. Many Android devices have pre-installed the Microsoft Bing and Yahoo! search applications. No matter which applications come pre-installed, the user can easily download Yahoo!, Microsoft’s Bing, and Google applications for free from the Android Market.
Rubin left Google in 2014 due to allegations of sexual harassment (albeit with a $90 million exit package). Eric Schmidt was CEO and executive chairman of Google from 2001 to 2015, then executive chairman and technical advisor of Google parent Alphabet through 2020. Neither has a current relationship with Google. But lies last forever. And Schmidt’s false statements to Congress were under penalty of perjury. Though the statute of limitations for perjury has run, representatives can still contact Schmidt, demand further testimony to explore his false statements, and publicly condemn his misconduct if they, like I, conclude it was perjury.
Affiliate network requirements require shopping plugins to “stand-down”—not present their affiliate links, not even highlight their buttons—when another publisher has already referred a user to a given merchant. Inexplicably, Microsoft Shopping often does no such thing.
The basic bargain of affiliate marketing is that a publisher presents a link to a user, who (the publisher hopes) clicks, browses, and buys. But if a publisher can put reminder software on a user’s computer or otherwise present messages within a user’s browser, it gets an extraordinary opportunity for its link to be clicked last, even if another publisher actually referred the user. To preserve balance and give regular publishers a fair shot, affiliate networks imposed a stand-down rule: If another publisher already referred the user, a publisher with software must not show its notification. This isn’t just an industry norm; it is embodied in contracts between publishers, networks, and merchants. (Terms and links below.)
In 2021, Microsoft added shopping features to its Edge web browser. If a user browses an ecommerce site participating in Microsoft Cashback, Edge Shopping open a notification, encouraging a user to click. Under affiliate network stand-down rules, this notification must not be shown if another publisher already referred that user to that merchant. Inexplicably, in dozens of tests over two months, I found the stand-down logic just isn’t working. Edge Shopping systematically ignores stand-down. It pops open. Time. After. Time.
This is a blatant violation of affiliate network rules. From a $3 trillion company, with ample developers, product managers, and lawyers to get it right. As to a product users didn’t even ask for. (Edge Shopping is preinstalled in Edge which is of course preinstalled in Windows.) Edge Shopping used to stand down when required, and that’s what I saw in testing several years ago. But later, something went terribly wrong. At best, a dev changed a setting and no one noticed. Even then, where are the testers? As a sometimes-fanboy (my first long-distance call was reporting a bug to Microsoft tech support!) and from 2018 to 2024 an employee (details below), I want better. The publishers whose commissions were taken—their earnings hang in the balance, and not only do they want better, they are suing to try to get it. (Again, more below.)
Contract provisions require stand-down
Above, I mentioned that stand-down rules are embodied in contract. I wrote up some of these contract terms in January (there, remarking on Honey violations from a much-watched video by MegaLag). Restating with a focus on what’s most relevant here (with emphasis added):
Commission Junction Publisher Service Agreement: “Software-based activity must honor the CJ Affiliate Software Publishers Policy requirements… including … (iv) requirements prohibiting usurpation of a Transaction that might otherwise result in a Payout to another Publisher… and (v) non-interference with competing advertiser/ publisher referrals.”
Rakuten Advertising Policies: “Software Publishers must recognize and Stand-down on publisher-driven traffic… ‘Stand-down’ means the software may not activate and redirect the end user to the advertiser site with their Supplier Affiliate link for the duration of the browser session. … The [software] must stand-down and not display any forms of sliders or pop-ups to prompt activation if another publisher has already referred an end user.” Stand down must be complete: In a stand-down situation, the publisher’s software “may not operate.”
Impact “Stand-Down Policy Explained”: Prohibits publishers “using browser extensions, toolbars, or in-cart solutions … from interfering with the shopping experience if another click has already been recorded from another partner.” These rules appear within an advertiser’s “Contracts” “General Terms”, affirming that they are contractual in nature. Impact’s Master Program Agreement is also on point, prohibiting any effort to “interfere with referrals of End Users by another Partner.”
Awin Publisher Code of Conduct: “Publishers only utilise browser extensions, adware and toolbars that meet applicable standards and must follow “stand-down” rules. … must recognise instances of activities by other Awin Publishers and “stand-down” if the user was referred to the Advertiser site by another Awin Publisher. By standing-down, the Publisher agrees that the browser extension, adware or toolbar will not display any form of overlays or pop-ups or attempt to overwrite the original affiliate tracking while on the Advertiser website.”
Edge does not stand-down
In test after test, I found that Edge Shopping does not stand-down.
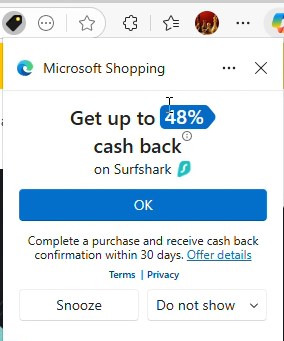
In a representative video, from testing on November 28, 2025, I requested the VPN and security site surfshark.com via a standard CJ affiliate link.
From video at 0:01
CJ redirected me to Surfshark with a URL referencing cjdata, cjevent, aff_click_id, utm_source=cj, and sf+cs=cj. Each of those parameters indicated that this was, yes, an affiliate redirect from CJ to Surfshark .
From video at 0:04
Then Microsoft Shopping popped up its large notification box with a blue button that, when clicked, invokes an affiliate link and sets affiliate cookies.
From video at 0:08
Notice the sequence: Begin at another publisher’s CJ affiliate link, merchant’s site loads, and Edge Shopping does not stand-down. This is squarely within the prohibition of CJ’s rules.
Edge sends detailed telemetry from browser to server reporting what it did, and to a large extent why. Here, Edge simultaneously reports the Surfshark URL (with cjdata=, cjevent=, aff_click_id=, utm_source=cj, and sf_cs=cj parameters each indicating a referral from CJ) (yellow) and also shouldStandDown set to 0 (denoting false/no, i.e. Edge deciding not to stand down) (green).
POST https://www.bing.com/api/shopping/v1/savings/clientRequests/handleRequest HTTP/1.1
...
{"anid":"","request_body":"{\"serviceName\":\"NotificationTriggering\",\"methodName\":\"SelectNotification\",\"requestBody\":\"{\\\"autoOpenData\\\":{\\\"extractedData\\\":{\\\"paneState\\\":{\\\"copilotVisible\\\":false,\\\"shoppingVisible\\\":false}},\\\"localData\\\":{\\\"isRebatesEnabled\\\":true,\\\"isEdgeProfileRebatesUser\\\":true,\\\"shouldStandDown\\\":0,\\\"lastShownData\\\":null,\\\"domainLevelCooldownData\\\":[],\\\"currentUrl\\\":\\\"https://surfshark.com/?cjdata=MXxOfDB8WXww&cjevent=cb8b45c0cc8e11f0814803900a1eba24&PID=101264606&aff_click_id=cb8b45c0cc8e11f0814803900a1eba24&utm_source=cj&utm_medium=6831850&sf_cs=cj&sf_cm=6831850\\\" ...
With a standard CJ affiliate link, and with multiple references to “cj” right in the URL, I struggle to see why Edge failed to realize this is another affiliate’s referral. If I were writing stand-down code, I would first watch for affiliate links (as in the first screenshot above), but surely I’d also check the landing page URL for significant strings such as source=cj. Both methods would have called for standing down.
Another notable detail in Edge’s telemetry is that by collecting the exact Surfshark landing page URL, including the PID= parameter (blue), Microsoft receives information about which other publisher’s commission it is taking. Were litigation to require Microsoft to pay damages to the publishers whose commissions it took, these records would give direct evidence about who and how much, without needing to consult affiliate network logs. This method doesn’t always work—some advertisers track affiliates only through cookies, not URL parameters; others redirect away the URL parameters in a fraction of a second. But when it works, more than half the time in my experience, it’s delightfully straightforward.
Additional observations
If I observed this problem only once, I might ignore it as an outlier. But no. Over the past three weeks, I tested a dozen-plus mainstream merchants from CJ, Rakuten Advertising, Impact, and Awin, in 25+ test sessions, all with screen recording. In each test, I began by pasting another publisher’s affiliate link into the Edge address bar. Time after time, Edge Shopping did not stand-down, and presented its offer despite the other affiliate link. Usually Edge Shopping’s offer appeared in a popup as shown above. The main variation was whether this popup appeared immediately upon my arrival at the merchant’s home page (as in the Surfshark example above), versus when I reached the shopping cart (as in the Newegg example below)s.
In a minority of instances, Edge Shopping presented its icon in Edge’s Address Bar rather than opening a popup. While this is less intrusive than a popup, it still violates the contract provisions (“non-interference”, “may not activate”, “may not operate”, may not “interfere”, all as quoted above). Turning blue to attract a user’s attention—this invites a user to open Edge Shopping and click its link, causing Microsoft to claim commission that would otherwise flow to another publisher. That’s exactly what “non-interference” rules out. “May not operate” means do nothing, not even change appear in the Address Bar. Sidenote: At Awin, uniquely, this seems to be allowed. See Publisher Code of Conduct, Rule 4, guidance 4.2. For Awin merchants, I count a violation only if Edge Shopping auto-opened its popup, not if it merely appeared in the Address Bar.
Historically, some stand-down violations were attributed to tricky redirects. A publisher might create a redirect link like https://www.nytimes.com/wirecutter/out/link/53437/186063/4/153497/?merchant=Lego which redirects (directly or via additional steps) to an affiliate link and on to the merchant (in this case, Lego). Historically, some shopping plugins had trouble recognizing an affiliate link when it occurred in the middle of a redirect chain. This was a genuine concern when first raised twenty-plus years ago (!), when Internet Explorer 6’s API limited how shopping plugins could monitor browser navigation. Two decades of improvements in browser and plugin architecture, this problem is in the past. (Plus, for better or worse, the contracts require shopping plugins to get it right—no matter the supposed difficulty.) Nonetheless, I didn’t want redirects to complicate interpretation of my findings. So all my tests used the simplest possible approach: Navigate directly to an affiliate link, as shown above. With redirects ruled out, the conclusion is straightforward: Edge Shopping ignores stand-down even in the most basic conditions.
I mentioned above that I have dozens of examples. Posting many feels excessive. But here’s a second, as to Newegg, from testing on December 5, 2025.
Litigation ongoing
Edge’s stand-down violations are particularly important because publishers have pending litigation about Edge claiming commissions that should have flowed to them. After MegaLag’s famous December 2024 video, publishers filed class action litigation against Honey, Capital One, and Microsoft. (Links open the respective dockets.)
I have no role in the case against Microsoft and haven’t been in touch with plaintiffs or their lawyers. If I had been involved, I might have written the complaint and Opposition to Motion to Dismiss differently. I would certainly have used the term “stand-down” and would have emphasized the governing contracts—facts for some reason missing from plaintiffs’ complaint.
Microsoft’s Motion to Dismiss was fully briefed as of September 2, and the court is likely to issue its decision soon.
Microsoft’s briefing emphasizes that it was the last click in each scenario plaintiffs describe, and claims that last click makes it “entitled to the purchase attribution under last-click attribution.” Microsoft ignores the stand-down requirements laid out above. Had Microsoft honored stand-down, it would have opened no popup and presented no affiliate link—so the corresponding publisher would have been the last click, and commission would have flowed as plaintiffs say it should have.
Microsoft then remarks on plaintiffs not showing a “causal chain” from Microsoft Shopping to plaintiffs losing commission, and criticizes plaintiffs’ causal analysis as “too weak.” Microsoft emphasizes the many uncertainties: customers might not purchase, other shopping plug-ins might take credit, networks might reallocate commission for some other reason. Here too, Microsoft misses the mark. Of course the world is complicated, and nothing is guaranteed. But Microsoft needed only to do what the contracts require: stand-down when another publisher already referred that user in that shopping session.
Later, Microsoft argues that its conduct cannot be tortious interference because plaintiffs did not identify what makes Microsoft’s conduct “improper.” Let me leave no doubt. As a publisher participating in affiliate networks, Microsoft was bound by networks’ contracts including the stand-down terms quoted above. Microsoft dishonored those contracts to its benefit and to publishers’ detriment, contrary to the exact purpose of those provisions and contrary to their plain language. That is the “improper” behavior which plaintiffs complain about. In a puzzling twist, Microsoft then argues that it couldn’t “reasonably know[]” about the contracts of affiliate marketing. But Microsoft didn’t need to know anything difficult or obscure; it just needed to do what it had, through contract, already promised.
Microsoft continues: “In each of Plaintiffs’ examples, a consumer must affirmatively activate Microsoft Shopping and complete a purchase for Microsoft to receive a commission, making Microsoft the rightful commission recipient if it is the last click in that consumer’s purchase journey.” It is as if Microsoft’s lawyers have never heard of stand-down. There is nothing “rightful” about Microsoft collecting a commission by presenting its affiliate link in situations prohibited by the governing contracts.
Microsoft might or might not be right that its conduct is acceptable in the abstract. But the governing contracts plainly rule out Microsoft’s tactics. In due course maybe plaintiffs will file an amended complaint, and perhaps that will take an approach closer to what I envision. In any event, whatever the complaint, Microsoft’s motion to dismiss arguments seem to me plainly wrong because Microsoft was required by contract to stand-down—and it provably did not.
***
In June 2025, news coverage remarked on Microsoft removing the coupons feature from Edge (a different shopping feature that recommended discount codes to use at checkout) and hypothesized that this removal was a response to ongoing litigation. But if Microsoft wanted to reduce its litigation exposure, removing the coupons feature wasn’t the answer. The basis of litigation isn’t that Microsoft Shopping offers (offered) coupons to users. The problem is that Microsoft Shopping presents its affiliate link when applicable contracts say it must not.
My time from 2018 to 2024, as an employee of Microsoft, is relevant context. I proposed Bing Cashback and led its product management and business development through launch. Bing Cashback put affiliate links into Bing search results, letting users earn rebates without resorting to shopping plugins or reminders, and avoiding the policy complexities and contractual restrictions on affiliate software. Meanwhile, Bing Cashback provided a genuine reason for users to choose Bing over Google. Several years later, others added cashback to Edge, but I wasn’t involved in that. Later I helped improve the coupons feature in Edge Shopping. In this period, I never saw Edge Shopping violate stand-down rules.
I ended work with Bing and Edge in 2022, after which I pursued AI projects until I resigned in 2024. I don’t have inside knowledge about Edge Shopping stand-down or other aspects of Microsoft Cashback in Edge. If I had such information, I would not be able to share it. Fortunately the testing above requires no special information, and anyone with Edge and a screen-recorder can reproduce what I report.
MDL docket originated August 12, 2021. First filing as to spoliation May 30, 2025.
May 30, 2025 letter presents MDL Plaintiffs’ request to file motions seeking an adverse inference against Google based on its spoliation — grounded in its scheme to encourage employees to use Google Chat set to automatically delete messages for employees subject to litigation hold; its failure to ensure that employees complied with litigation holds; and its policy to mislabel sensitive information as “privileged and confidential” to attempt to avoid discovery.
Explains the evidence of Google’s intent to spoliate evidence, including employees discussing what information they should discuss where and how.
Summarizes critical remarks from other courts that examined Google’s spoliation. Donato: “a permissive adverse inference instruction is a reasonable and proportionate remedy to Google’s intentional failure to preserve relevant evidence.” Mehta: “Google’s failure to preserve chat messages might” “warrant” sanctions. Brinkema: “systematic disregard of the evidentiary rules regarding spoliation of evidence … may well be sanctionable.”
Criticizes’s Google’s “systematic abuse of privilege” including by CEO Sundar Pichai personally, noting his admission that he “marked e-mails privileged, not because [he was] seeking legal advice, but just to indicate that they were confidential.” Notes criticism from other courts: Donato: “frankly astonishing abuse of the attorney-client privilege designation to suppress discovery.” Mehta: “the court is taken aback by the lengths to which Google goes to avoid creating a paper trail for regulators and litigants.” Brinkema: “misuse of the attorney-client privilege may well be sanctionable.” Notes that other courts only withheld an adverse instruction because it would have been superfluous given the liability findings already made.
As to intent: “Google instructed its employees to use “history off” chats for work-related communications because they would not be preserved for future litigation.” Notes that in the 2008 Walker Memo, Google both remarked on “significant legal and regulatory matters” and announced that it would set Chat history to “off the record” — indicating that the former motivated the latter, which the motion claims is improper. Remarks on Google training to employees: “Google taught employees that sending an ‘off the record’ Chat is ‘[b]etter than sending [an] email’ because ‘off the record’ Chats ‘are not retained by Google as emails are.’”
As to Google’s approach to preservation: Google put “the onus … on each individual employee under a litigation hold to determine in real time whether a particular part of a particular Chat might be relevant to any actual or reasonably anticipated litigation,” and says Google failed to provide suitable guidance to those employees. Google did not instruct employees to turn history on for discussions related to a litigation hold until October 2021. Google did not audit whether employees complied with litigation holds.
As to untimeliness of Google’s preservation: Notes that Google claimed privilege over documents relating to ad tech as early as 2006, and specifically anticipated litigation in this area by 2013. Notes Texas’s first Civil Investigative Demand to Google in September 2019. Yet 61 of 202 custodians in this case were not placed on a litigation hold until 2022, more than 3 years after that CID was issued and more than 2 years after Google told plaintiffs that it had implemented appropriate litigation holds. (Table of delays in hold dates.)
As to specific individuals who failed to preserve: Reports that Google CEO Sundar Pichai never switched on Chat history, not a single time, to preserve even a single communication. Reports that Google failed to preserve 96% of Pichai’s chats from a two-month period for which partial data is available.
As to the volume of Chat messages at issue: Claims the relevant Google employee-custodians sent and received about 20,000 Chat messages per employee per year, totaling between 2.8 and 4 million Chat messages per year across all employees at issue in this litigation.
As to remedy: Asks the Court to “(1) instruct the jury that (i) Google had an obligation to preserve Chats, (ii) Google intentionally deleted millions of Chats, and (iii) the jury must presume the deleted Chats contained information unfavorable to Google, (2) find that Chats likely would have provided further evidence against Google’s motions for summary judgment; (3) award Plaintiffs’ fees and costs associated with this motion.”
January 31, 2025 supplemental expert report of Jacob Hoschstetler as to the scope of Chat messages lost due to Google’s failure to preserve (87% of messages lost, at least 18,566/21,269). Hoschstetler also reports that not a single custodian in the Log Dataset produced by Google personally switched the history to “on” for any of the conversations during the period of that log, although Google said it instructed employees to do so if discussing a topic within the scope of their litigation hold. 94.5% of chat conversations had chat history turned off for at least some of the time period covered by the Log Dataset. For Google CEO Sundar Pichai, more than 96% of Chat messages were not preserved, and in a single conversation, more than 300 messages were not preserved.
Uber this week emailed San Francisco users of Uber Teen (a service that transports kids ages 13-17) both to announce that it is suspending that service in California, and to blame new California Public Utilities Commission rules for that closure. Uber claims CPUC made “new and onerous changes” which left the company “no choice” except to suspend service. I emphatically disagree. The problem, such as it is, is of Uber’s own creation — and Uber had and has a viable path forward.
Narrowly: Nothing forces Uber to suspend service. Uber could comply with the CPUC’s requirement and continue service by implementing reasonable driver registration precautions, in fact the same precautions that competitor HopSkipDrive has used for years. The words “no choice” have literal meaning, and that’s just not the situation here. The real issue is that Uber disagrees with CPUC’s requirement that it check driver fingerprints, arguing that its background checks suffice. But that disagreement does not compel Uber to discontinue service. Many people and companies disagree with many laws and regulations. The normal process is to submit comments in a legislative or rulemaking process, to sue if you think the rule is so broken that (say) it’s unconstitutional, to invoke political remedies such as replacing whoever imposed the rule, and ultimately to honor the democratic process by complying. Win some, lose some, and hope to win more than you lose. In contrast, Uber’s approach is a threat: Either the regulation goes Uber’s way, or Uber will cease service.
When an adult is being tasked to provide a service to a minor, the adult is placed in a position of trust, responsibility, and control over California’s most vulnerable citizenry—children. Not conducting a fingerprint-based background check to identify adults with disqualifying arrests or criminal records would place the unaccompanied minor in a potentially dangerous, if not life-threatening situation. That is why California Assembly Bill 506 … requir[es] that administrators, employees, or regular volunteers of youth service organizations undergo a background check that includes fingerprinting.
In response, Uber claims that its background checks work well and are sufficient. Who’s right? Consider the broader context. Uber’s background checks rightly deny accounts to drivers with bad driving records, prior ejections from Uber’s platform, or no documentation establishing right to work. But if a driver can’t pass those checks, the standard strategy is to “borrow” an account from someone who can. Many people tolerate a certain amount of this for ordinary adult rides. As the CPUC explains above, the stakes are higher when transporting minors unaccompanied. In that special context, higher standards are no surprise.
If fingerprinting drivers were massively costly, it might nonetheless be an unwise investment — a cost exceeding plausible benefits. For all its protestations to CPUC and to users, Uber never quite explains why it’s (supposedly) so difficult to do what CPUC specifies. If I had to implement CPUC’s requirement, I’d collect driver fingerprints through smartphones or at the inspection centers that check drivers’ vehicles. This sounds like software plus business operations — some work, but proportional to the business opportunity of the Uber Teen service. It feels particularly reasonable because fingerprint security is increasingly common. While an employee at Microsoft, I had to present my fingerprint to my phone’s Authenticator app to activate two-factor authentication to access company resources. CPUC similarly seeks fingerprint security for drivers transporting unaccompanied minors. Why should a minor’s safety get less protection than a company’s secrets?
In a filing before the CPUC, Uber argued that higher registration requirements for Uber Teen drivers would reduce the number of drivers, hence increasing prices to passengers. But if Uber Teen rides pay drivers materially more than regular rides, drivers have corresponding incentive to get registered. The only sustainable price gap is the result of the time or difficulty of registration, but by all indications that’s minimal. If a driver’s registration burden is small, as it should be, the price gap should also be small. Supply and demand.
The most charitable reading of Uber’s message to users is that Uber would like to comply with CPUC’s requirements, but had too little time. Yet here too, Uber’s position is in tension with the facts. Uber had long known CPUC took a dim view of its service to teens, including correspondence with CPUC staff as early as January 5, 2024. On March 14, 2024, Uber filed a motion seeking approval of its service for teens. CPUC’s rulemaking was published on October 30, 2024, giving Uber a further 30 days to come into compliance. And Uber says it intends to continue service for teens until December 23, 2024. That marks 353 days since Uber was on notice of the disagreement, and 54 days between CPUC’s rulemaking and Uber’s scheduled withdrawal of service. If Uber had used those 54 days effectively, not to mention those 353, there’s every indication it could have met CPUC’s requirements. If Uber needed additional time, it could have explained how long and why. Nothing about CPUC’s approach or timetable compelled Uber to withdraw its service for teens.
Any Uber complaint about too little time to comply is further undermined by CPUC’s 2016 guidance and Uber’s reply. In particular, CPUC specifically put Uber on notice that it would need an additional approval to launch service for minors, and Uber promised to discuss with CPUC before launching any such service. So any new urgency is of Uber’s creation.
Enlisting users in its fight against CPUC
Nothing could be more fundamental to the Democratic process than informed constituents making their views heard. And the CPUC did solicit comments, though for whatever reason none were received.
But what Uber envisions now is something quite different than informed public comments. Instead, Uber provides its users with, at most, a portion of the information they would need to evaluate the disagreement. Consider: Uber’s email to users claims “new rules requiring significant changes to Teen accounts” but doesn’t say a word about what those rules are or what changes would be required. (In fact by all indications the changes are only to driver verifications, not to user accounts.) While CPUC posted a detailed rulemaking with discussion of rationale and alternatives, Uber doesn’t mention any such document available — not a link, not even the title of the proceeding. Uber’s email asks users to “let the CPUC know” “if teen rides are important to your family”, but the question before CPUC isn’t whether teen rides are important, but rather what verifications are appropriate to provide sufficient safety for those rides.
When Uber delivers user comments to CPUC, will it deliver them all? Or just those that support its position? There’s reason to suspect shenanigans: In 2015, Uber delivered 8 boxes of supposed user petitions to regulators in St. Louis, but the boxes turned out to contain only water bottles.
Uber’s attempt to turn users against CPUC is reminiscent of the company’s infamous 2015 “De Blasio mode” which mobilized users against proposed New York regulations. There, as here, Uber treated users like pawns in an astroturf operation — giving users incomplete information designed to prompt an immediate forceful response. Uber plainly hopes to flood CPUC with complaints about regulation supposedly causing suspension of Uber Teen. But users might have second thoughts if they knew the full picture. Users surely value the low prices Uber emphasizes, but for transporting unaccompanied minors, safety is bound to be a priority too. Ultimately Uber gave users no way to judge whether its protections are sufficient or whether CPUC’s requirements would actually be useful. With the limited context Uber provides, what can a user usefully tell CPUC? At a minimum, Uber should have linked to the CPUC rules at issue, should have summarized what it saw as most objectionable, and should have offered a specific alternative. A better approach, to give users a full sense of the debate, would have summarized the rationale CPUC offered for its approach, fairly and evenhandedly, so users would be closer to deciding for themselves. Predictably, Uber did none of this.
These days, Uber seeks to portray itself as kinder and gentler, supposedly reformed from its scandalous peak of 2015-2017. Uber now sponsors NPR. Chief Legal Officer Tony West is Kamala Harris’s brother-in-law and campaign advisor. But has the leopard really changed its stripes? Tellingly, Uber’s terms of service still require users with disputes to file arbitrations (not lawsuits) before an arbiter Uber chooses, and ban users from filing class actions so a single set of lawyers can efficiently pursue the claim for everyone affected. Suppose Uber gets its way and returns to transporting unaccompanied minors without the fingerprints CPUC requires. If something terrible happens — a kidnapping, assault, or worse — Uber’s terms says passengers cannot even sue. This episode smacks of the Uber of a decade ago. I’ve added it to Uberscandals.org in lobbying, regulators, and safety.
Google has been in the news not just for multiple litigation losses on the merits of antitrust cases, but also for repeated failures to preserve and produce relevant documents. Let me offer five themes from the discovery proceedings.
First, Kent Walker’s 2008 memo warned employees against putting their frank ideas into documents that might be “used against” Google in litigation. In the same memo, Walker also announced a reduction in retention for certain chats, all but instructing employees to move sensitive discussions to off-the-record chats. The United States called the Walker memo “an early hallmark of Google’s intent to deprive litigants of evidence.” Indeed, with Walker counseling employees on what to retain, litigants must wonder whether surviving documents truly reflect genuine business discussions, versus a strategically-incomplete record created in anticipation of litigation. Examining Google’s documents in the search case, Judge Mehta remarked:
[T]he court is taken aback by the lengths to which Google goes to avoid creating a paper trail for regulators and litigants. It is no wonder then that this case has lacked the kind of nakedly anticompetitive communications seen in Microsoft and other Section 2 cases. … Google clearly took to heart the lessons from these cases. It trained its employees, rather effectively, not to create ‘bad’ evidence.
Second, Google employees moved communications out of email and into “chat” where, as Walker indicated, Google did not preserve documents by default. In any 1:1 chat, even among employees whose business responsibilities made them subject to document preservation obligations, Google’s internal chat tool defaulted to not saving materials—thereby causing them to be deleted and not provided in litigation. So too for group chats where an employee set history to off. Of course employees knew this and often discussed the need to move to an off-the-record environment exactly to avoid document retention. Employees’ use of these methods wasn’t some rogue tactic, nor any surprise; quite the contrary, Google’s training encouraged exactly this, calling chat “better than email” because it is “not retained by Google as emails are.” Even current Google CEO Sundar Pichai participated in the ruse, remarking “also can we change the setting of this group to history off.” Like others, Pichai knew exactly what he was doing: In a special hearing in the search case as Judge Mehta investigated Google’s discovery violations, Pichai testified that he “was aware” that default chat settings and history-off chats deleted messages after just 24 hours even if a litigation hold required their retention.
Third, Google employees practiced “fake privilege”—adding an attorney to an email thread not genuinely to seek legal advice, but to create a veneer of privilege. For years, Google withheld such emails from its litigation adversaries, and only under pressure from litigants did Google recently begin to reclassify documents. Even when Google ultimately de-privileged some documents, this caused substantial delay to litigation and, as the Department of Justice remarked in the ads case, created “administrative chaos” including Google retroactively “downgrading” the privilege of more than 40,000 documents. Here too, the problem goes all the way up to Google CEO Sundar Pichai, who admitted adding lawyers when he was “seeking confidentiality for the document” and not “really seeking legal advice.”
Fourth, Google’s most senior executives showed a lack of candor in both their memories and their document preservation practices. This problem first arose in Viacom v. Google copyright litigation. For example, Google co-founder Larry Page was strikingly evasive when deposed in that case, stating 132 times “I don’t recall,” including on subjects that were widely discussed internal to Google, at Google’s board, and even in public. Meanwhile, then-CEO Eric Schmidt unapologetically reported that “it was my practice to delete or otherwise cause the e-mails that I read to go away as quickly as possible,” despite participating in discussions on subjects where litigation was foreseeable, actually foreseen, or for that matter underway. Viacom summarized the problem:
This Court can decide whether these key executives and witnesses behaved with the level of candor and respect for the legal process that this Court has a right to expect from senior executives of important public companies.
In comparison, Sundar Pichai’s recent approach is, in these respects, an improvement. Yes, Pichai improperly used chat to avoid creating an unfavorable record. And yes, he added lawyers to a thread to try to increase confidentiality (not actually seeking legal advice). But when called to testify under oath, at least Pichai told the truth about what he did and why. At least sometimes. In Epic Games, Plaintiffs presented evidence of Pichai not just asking for history to be turned off, but trying to delete history himself—an action which Pichai said he “d[id]n’t recall.”
Ultimately there’s no escaping the role of senior executives in these discovery violations. Above I remarked on discovery disputes implicating CEO Pichai, co-founder Page, and former CEO Schmidt. Also at issue: Susan Wojcicki, then-CEO of YouTube, who proposed that Robert Kyncl (then Chief Business Officer of YouTube) “send via Hangouts” because that is “off the record,” or if not, she “can change to off the record.” And Kent Walker, whose guidance and policy change set this mess in motion, was and remains Google’s General Counsel. I do not even attempt to list the countless senior vice presidents and vice presidents who appear in the discovery violation proceedings. Of Google’s many participating executives, only Walker currently faces even the possibility of a personal sanction—a request from American Economic Liberties Project and others that the California State Bar investigate and penalize according to its rules.
Fifth, Google’s discovery violations have been unfolding in slow-motion for years, with no real penalty to date. Below, I trace Google’s discovery tactics back to Viacom v. Google—where discovery questions were only partially briefed, and never decided, but nonetheless show the beginnings of this problem more than a decade ago. This year, the DOJ’s two antitrust cases against Google revealed many new details about Google’s discovery tactics. Yet Google Play Store Antitrust Litigation in 2022 uncovered the basic problem—Google training employees to use chat rather than email, and not retaining those chats. Two years later, courts are still grappling with the problem and exploring what, if anything, to do about it.
***
Many excellent articles summarize courts’ decisions about Google document preservation. But these articles largely focus on what judges wrote, without the color that comes from detailed briefing by plaintiffs, not to mention extended quotes from the underlying documents. In the pages linked below, I organize (what I hope to be) most relevant exhibits, briefing, and decisions in the cases at issue. Realistically, I don’t have it all—but with the deep links I offer (to detailed filings with detailed quotes) and with the free online tools I invoke (where full dockets are organized and, mostly, full-text searchable), diligent readers are positioned to find even more. Send suggestions for addition.
For those who have followed Google spoliation proceedings, the newest three cases are familiar—though I’ve found documents and quotes not elsewhere called out. Meanwhile, the 2010 Viacom v. Google proceedings are also worth a read because, more than a decade earlier, that case raised much the same questions—whether Google honored its discovery obligations, and if not, what to do about it.
Filed January 24, 2023. First filing as to discovery violations: August 2, 2024.
Case allegation: Google used unlawful methods to dominate the ad tech stack, including buying control of key tools, locking out rivals, buying and killing a burgeoning competitor, and “drying out” other competition. Complaint.
Case disposition: Bench trial complete. Awaiting decision.
On document preservation generally: “Aware of the risk of ‘several significant legal and regulatory matters’, Google … trained its employees to channel discussion of ‘hot topics’ that ‘may be used against [Google]’ … to Google’s internal instant-message chat tools [where] absent manual intervention by business employees on a chat-by-chat basis, all internal chat communications would be automatically destroyed after 24 hours. Google adopted this auto-delete policy knowing that its employees’ communications could someday be scrutinized by a Court such as this one.”
On purpose and intent of preservation failures: “Google’s spoliation is the predictable and intended result of the intersection of Google’s broader policies and culture with its specific litigation choices here. Google’s stated goal … was to avoid having its ‘sensitive’ communications ‘discovered by an adversary and used against … Google.’” “[N]ot only did Google choose to continue its policy of auto-deletion of chats after 24 hours, Google also chose to delay placing many of its employees on a litigation on hold in this case until months (or even years) after Google was required to preserve their documents.” “Employees … chose to make chats ‘history off’ … for the express purpose of evading discovery.” “Despite Google’s anticipation of litigation on [specified] subjects …, and Google’s agreement to produce relevant documents… Google continued its policy of automatically deleting chats.” “Google’s document production contains numerous examples of employees seeking to make chats ‘history off’ to ensure they were not discoverable.”
On effects of preservation failures: “Plaintiffs were deprived of valuable, likely irreplaceable, discovery. … The total volume of chats produced by Google in this case is remarkably low in proportion to the volume of other communications (e.g. emails) produced from the same employees.” “Chats are an important window into the candid thought processes, intentions, and observations of [employees … by design, one of the only places in which employees were free to write down candid observations or opinions relating to the core issues in this case.” “Google’s conduct … is deeply troubling. Google has stretched and weaponized the attorney-client privilege and its protections; it has intentionally spoliated evidence; and despite branding itself as a world-class technology innovator, it has engaged in a series of repeated errors and delays in the production of discovery, all of which have served Google’s broader, strategic ends of impeding its adversaries’ access to information to which they are entitled.”
On “Communicate with Care” training: Remarked that this training “advised Google employees that discussing sensitive topics via ‘off the record’ chats was ‘[b]etter than sending [an] email’ because such charts ‘are not retained by Google as emails are’.” “Second, ‘Communicate with Care’ cultivated a corporate culture of hiding documents from discovery by training Google employees to leverage pretextual claims of privilege, including detailed instructions on how to craft an email that will appear to be subject to the attorney-client privilege.”
On remedy: “The Court should presume the spoliated chats were unfavorable to Google.” “The Court may limit the testimony of witnesses who participated in the spoliation conduct at issue by precluding them from offering testimony supportive of Google on issues such as intent, procompetitive justifications, and the effect of Google’s challenged conduct on competition.” “The Court may preclude Google from arguing that a paucity of direct, contemporaneous evidence supports an inference that no additional evidence exists.” “The Court may sanction Google by admonishing, censuring, or otherwise publicly reprimanding it.” “When, as here, a litigant violates those obligations in ways that compromise or undercut the truth-seeking function of the judicial process, they must be held accountable. If not, Google and other companies aware of this litigation will continue to encourage employees to adopt careless or evasive discovery-related practices, particularly when faced with similar high-stakes litigation.”
Kent Walker Memo (September 16, 2008). “Please do think twice before you write about hot topics.” “To help avoid inadvertent retention of instant messages, we have decided to make ‘off the record’ the Google corporate default setting for Google Talk.”
Employee training as to “Communicate With Care.” Discusses what an employee might do when seeking to communicate on a sensitive subject. To a suggestion to send an email, remarks “Don’t send the email. Chat ‘off the record’ via Hangouts instead.” The training instructs that off the record chat is “Better than sending the email” because such chats are “not retained by Google as emails are.” See also Antitrust Basics for Search Team (March 2011).
Vip Andleigh: “lets keep confi, we can also turn off history. if i see something important, i’ll note it down somewhere”
Amin Charaniya: “btw didnt realize history is on for us” “mind if I turn it off?” “sure” [end of chat]
Amin Charaniya with dardelean@ and touma@: “this group is on record . . . we should kill it and create one that is single threaded and off the record” “who is in charge with creating this room? I really feel super uncomfortable us continuing this on the record” “im gonna create a new room and kill this one” “I copied everyone into a new room . . . let’s stop using this one” [end of chat]
Anthony Chavez: “separate topic – this chat room has history / is persisted? . . . can we configure it to be transient” “okay, let me create a new one right now. It’ll still be a space.” [end of chat]
Nash Islam: “too sensitive for email so keep on ping?”
Adam Juda: “I see that History is on in this chat. If that can’t be changed, can I please be removed from this discussion?”
Aparna Pappu: “Please keep history off on this legally sensitive chat room”
Martin Pal with tris@ :”We want chat history on? I would generally prefer for us to keep history off.” … “let’s turn it off then” [end of chat]
Prabhakar Raghavan: “ugh pl stop this chat, for some reason History is on”
Prabhakar Raghavan: “I’m going to kill this room and re-create as a group chat with History OFF.”
Danielle Romain: “I’m not supportive of turning history on. The discussion that started this thread gets into legal and potentially competitive territory, which I’d like to be conscientious of having under privilege. So that you’re aware, when history is on, it’s discoverable. Sometimes that’s totally fine but I’d like to stick to the default of history off.”
Bonita Stewart and Jason Washing: “btw you might want to turn your chat history off” “geez . . . for sure! . . . thank you!” [end of chat]
Bonita Stewart and Cyrus Beagley: “on your chats you have the history turned on. we are advised to turn history off so messages are cleared after 24 hours” “oh I didn’t know that … I’ll turn it off then…”
Appendix E: Plaintiffs’ chart showing a sharp increase of chats produced after Google suspended auto-delete. Plaintiffs remark on “at least two trial witnesses whose volume of substantive chats dramatically increased (eight times over) when Google suspended auto-deletion (Nirmal Jayaram and George Levitte).”
Google’s Memorandum of Law in Opposition to Plaintiffs’ Motion for an Adverse Inference. “Plaintiffs’ motion is barred because it is untimely.” “Plaintiffs have not demonstrated, by clear and convincing evidence, that Google acted with the specific intent to deprive them of evidence.” “Plaintiffs have not demonstrated prejudice, a prerequisite to any form of sanction under Rule 37(e)(1).” “Plaintiffs have not demonstrated that any ESI—much less ESI relevant to their claims—was lost.” “Plaintiffs’ request for sanctions pursuant to the court’s inherent authority should be denied because Rule 37 controls.”
Reply Memorandum of Law in Further Support of Plaintiffs’ Motion for an Adverse Inference. “Google does not dispute that it failed to meet that obligation and destroyed relevant chats. Google does not deny that witnesses, including senior executives, used chats to discuss their work, including work relevant to this case. Nor does Google deny that it: (i) made ‘history off’ the default setting for chats, such that they would be deleted automatically after 24 hours; (ii) required individual employees to make cumbersome, in-the-moment decisions about a chat’s relevance to a litigation hold in order to preserve them; and, most concerning, (iii) trained employees to discuss ‘sensitive’ matters in ‘history off’ chats so they would not be ‘discovered by an adversary,’ all of which facilitated and encouraged destruction of work-related chats. Google does not dispute that this conduct went on for years, stopping only after this case was filed.” “When Google was faced with increasing exposure from litigation by government enforcement agencies, it took a calculated risk to create a system that would deprive its litigation adversaries of evidence. The Court need not guess or make an inference about that goal; the Walker Memo expressly stated it. Over time, Google (including witnesses here) consistently underscored and reinforced the messages from the Walker Memo with mandatory corporate trainings about avoiding ‘discoverable’ communications. Consistent with that corporate training, Google employees, including witnesses here, deliberately turned to ‘off the record’ chats to discuss sensitive material they did not want preserved and turned over in litigation.”
Identifies six distinct facts Google failed to disclose to the United States about its document destruction practices:
1. “History off” chats (an undefined term) were automatically deleted after 24 hours;
2. “History off” was the default chat setting, absent manual intervention;
3. Google employees were asked to manually override this default on a chat-by-chat basis;
4. Google conducted no oversight of whether employees were manually preserving chats;
5. Google trained its employees to use “history-off” chats as preferable to email to discuss “sensitive” topics, so that such discussions would not be discoverable; and
6. Google’s in-house lawyers instructed employees to keep their chats “history off” so that they would be automatically deleted
Flags specific instances of Google employees failing to preserve relevant documents:
document custodian “Ms. [Chetna] Bindra, whom Plaintiffs now know was on litigation hold in December 2019, proposed the next month that a group discussing Google’s ad targeting policies, including trial witness Nitish Korula, ‘do a ping thread with history off and without Nitish’ because Mr. Korula was on litigation hold.” – source
document custodian “Bindra in Feb. 2020: ‘The thread has history on. Using the other one.’” – source
document custodian Jason Washing “turning ‘history off’ while on litigation hold” – source
“relevant history-off chats from [Haskell] Garon in 2020, copied into email by another custodian but not found in Garon’s files” – source
“trial witness and then-head of ads business [Jerry] Dischler successfully proposing ‘a group chat that disappears after 24h’ for business discussion in 2020” – source
trial witness “[Aparna] Pappu’s efforts in 2020 to turn history off” – sources 1, 2, 3, 4
trial witness “Pappu in 2020 participating in a chat that abruptly ends when colleague states, ‘I could see this being done in a way that leads to law suits . . . Omfg . . . History is on, jesus . . . Sigh [end of chat]’” – source
trial witness “Pappu in Oct. 2019: ‘so weird I realized this one random topic is history on!’ [end of chat]” – source (thereby indicating that many other topics have history off)
trial witness “LaSala in Dec. 2020: ‘Jeff turned history on! . . . I should be careful now’)” – source
trial witness “LaSala proposing ‘history off’ chats for sensitive business discussions with trial witness Duke Dukellis months after new lit hold dates.” – source
Adam Lasnik explaining why he avoids “discoverable medium[s]” for “especially sensitive” topics, including “competitive landscape (monopoly, crushing competition, etc.)” and instead uses “off-the-record chats” to avoid messages “ending up in court” – source
then-CEO of YouTube Susan Wojcicki proposed that then-Chief Business Officer of YouTube Robert Kyncl “send via Hangouts” because that is “off the record” or if not she “can change to off the record” – source
Plaintiffs’ Post-Trial Proposed Findings of Fact and Conclusions of Law at heading “The Court Should Sanction Google for Its Spoliation of Chats.” “Google’s conduct has thwarted the Court’s truth-seeking function not only in this case but in several other cases” (citing Google Search [update caption]). Flags “Google’s repeated and persistent efforts to ensure its employees’ chats were deleted despite its known discovery obligations.” On that basis, argues that “The Court should … go beyond mere condemnation to ensure Google’s ‘contempt’ for its ‘discovery obligations’ receives the appropriate sanctions.” “Because Google acted ‘with the intent to deprive’ Plaintiffs of the use of chats in this litigation, the Court may ‘presume that the lost information was unfavorable’ to Google. Specifically, the Court may reasonably infer that intentionally deleted chats about ‘sensitive’ topics relevant to the claims in this case would have been unfavorable to Google on the core issues that were disputed at trial, including market definition, monopoly power, Google’s intent, the anticompetitive nature of Google’s conduct, and the harm Google’s conduct caused its competitors and customers.”
August 27, 2024 hearing. Transcript posted in the In re Google Digital Advertising Antitrust Litigation docket as document 1005 exhibit 2. There, Judge Brinkema said the Walker memo is an “incredible smoking gun” showing Google’s intent “to hide relevant information.” (15:9-20) Also quoted in part in Plaintiffs’ Post-Trial Proposed Findings of Fact and Conclusions of Law at heading “The Court Should Sanction Google for Its Spoliation of Chats.” Court called Google’s conduct “very serious” “clear abuse of the [attorney-client] privilege” and “absolutely inappropriate and improper.” “Had Google set the default settings for chats to history on, ‘the government could see … in this particular case somebody deleted [a chat], then you could focus on why was that deleted.’” “Because Google kept its default settings for chats to history off, ‘You’ve lost that ability in this case because everything is deleted unless it’s saved’.” “[T] his record creates a very serious problem for Google in terms of how much credibility the Court will be able to apply. Intent is a serious issue in this case, and I think it’s going to be a problem given this history.”
Filed October 20, 2020. First filing as to discovery violations: February 23, 2023.
Case allegation: Google unlawfully maintained monopolies in the markets for general search services, search advertising, and general search text advertising through anticompetitive and exclusionary practices. Complaint.
Case disposition: Opinion of August 5, 2024 finds Google has monopoly power in the general search text ads market, Google’s exclusive agreements foreclose a substantial share of the text ads market and allow Google to charge supra-competitive prices and degrade quality.
“By intentionally destroying employee chats and making repeated misleading disclosures to the United States, Google violated Rule 37(e) and is subject to sanctions for spoliation.”
“For years, Google empowered, and even encouraged, its employees to engage in ‘history off’ written communications—known by Google employees as ‘off the record’ chats—which were then automatically destroyed after 24 hours. Google even trained employees that ‘off the record’ chats, also known as Google Hangouts or instant messages, are ‘[b]etter than sending [an] email’ and ‘not retained by Google as emails are.’” “Google routinely destroyed these written communications. In fact, Google continued automatically deleting these ‘off the record’ chats after it reasonably anticipated litigation, throughout the United States’ investigation, and even when the company became a defendant in this litigation—every 24 hours up until February 8, 2023.” “Google repeatedly misrepresented its document preservation policies, which conveyed the false impression that the company was preserving all custodial chats.”
“Google’s refusal to suspend its auto-deletion policy earlier is especially notable in light of the sanctions motion filed in the Epic proceedings. Even after the plaintiffs in that case confronted Google with spoliation concerns, Google still withheld its 24-hour auto-deletion policy from the United States and continued to destroy written communications in this case.”
“Google knows that its employees use the ‘off-the-record’ functionality to avoid discovery.” Quoting an internal Google analysis: “when… History is Off, … there’s a higher likelihood that sensitive information is being discussed” and “[p]eople don’t want chat to be discoverable.”
Quotes Google policies and remarks purporting to preserve and produce all relevant documents. Quotes a Google Records Retention Policy which Google provided as part of an ESI Questionnaire from the Department of Justice: “With respect to legal holds, the policy states that “[a] legal hold suspends all deletion procedures in order to preserve appropriate records under special circumstances, such as litigation or governmental investigations.” (emphasis added by Plaintiffs in the filing) “Neither [that] policy, nor Google’s ESI Questionnaire responses, (1) discusses the existence of ‘off the record’ written communications; (2) explains how ‘off the record’ or history-off chats are treated; or (3) refers to a default, 24-hour deletion of any ESI.” Quotes Google’s claim that it was preserving all documents: “Google has put a legal hold in place. The legal hold suspends auto-deletion.” Explains that Google only admitted “off the record” chat deletion after the United States requested further materials incidental to the Epic sanctions motion.
On the importance of the deleted documents: “These deleted chats may have contained especially probative information and revealed candid discussions between key Google executives on relevant topics. As a result, the prejudice to the United States is substantial.” “[C]hats are often a rich source of evidence: employees tend to be more candid in informal modes of communication than they are over email or in presentations and memos.” “Chats are an even more significant source of evidence under the circumstances here, because Google has instructed employees to avoid discussing sensitive issues over email, including issues related to competition.”
On intentionality: “Google and its employees intentionally exploited its ‘off the record’ chat policy.” “[T]he company’s employees knew that history-off chats were not being preserved and exploited that fact to shield sensitive information from discovery.” “When Google warned employees against discussing sensitive matters over email, the company encouraged them to do so instead through off-the-record chats.” “Google’s exploitation of off-the-record chats belies any notion that this destruction was an honest mistake or an oversight.”
Calls out specific employees who used “history off” chat and employee discussions evading document retention obligations:
CEO Sundar Pichai: “can we change the setting of this group to history off”
Anna Kartasheva and Jim Kolotouros: “[W]e should chat live so you can get the history; best to not put in email.”
Purnima Kochikar: “the conversations in Rooms on Meet remain in perpetuity so please don’t discuss either topics in Rooms.”
Margaret Lam: “I’d prefer to have history off. … I talk about RSA related things all day and I don’t have history on for all my chats 🙂 … Ok maybe I take you off this convo”
Margaret Lam: “can I ask you to turn off history :)”
Christopher Li: “Is there no way to turn history off for these spaces?” “I don’t even see the option as an administrator.” “I’ll deprecate this group so we can use the other.”
Prabhakar Raghavan: “used “a ‘history off’ chat” in discussions about ‘how Chrome has affected our query volume.””
Sameer Samat: “pls keep in mind this chat history is not off”
David Sun: “If anyone wants to hear horror stories of chat histories being used in depositions at Google … just ask me and I can speak generally. … It’s bad news.”
Larry Yang: “Reminder: do not speculate on legal matters over email or (saved) chat”
“Since it’s a sensitive topic, I prefer to discuss offline or over hangout.”
“Let’s not talk about markets and market share via email.”
“When you want to talk about stuff that has legal ramifications, such as privacy, the way to discuss it is in person, and not in email / writing of any form (unless you consult with the lawyer cats/pm first :)”
“We should chat live so you can get the history; best to not put in email.”
“maybe we should discuss this ‘off the record’, I think [there’s] a lot to unpack here.”
Schramm: “Should we have history off for this?” “I think our chats about google products are more likely to come up in court”
Cdimon: “Since history is turned on, be mindful of putting anything discoverable here.”
Bill Richardson: “We have history off so that we can speak (more) freely.”
William Furr: “It’s easy to get carried away in chat and communicate with less care than you might with email.”
(Citations provided where findable. Many cited documents are under seal, so available only to the extent quoted in the memorandum.)
“Google did not disclose its chat destruction policy until January 2023.” “Google’s chat destruction policy was not reasonable.” “Deleting its preservation obligations to employees was unreasonable.” “Auto-deletion was unreasonable.” “It was inherently unreasonable for Google to default most chats to ‘history off’ and then automatically delete those chats for custodians under a litigation hold. That is especially true because Google recognized its employees’ use of ‘history off’ chats ‘to discuss sensitive topics’ and avoid discovery.“ “The United States was presumptively prejudiced because Google acted with an intent to deprive.” “[E]mployees discussed sensitive topics via chat because they knew other communication methods were subject to production. “
Quotes additional employees about hiding conversations from legal scrutiny: “I prefer not to be deposed for the contents of kappa chat… It needs to be history off”, “should we have history off for this?”, “Since history is turned on, be mindful of putting anything discoverable here…”
Google’s Memorandum in Opposition to Plaintiffs’ Motions for Sanctions. “Plaintiffs’ unreasonable delay in raising any objections bars their motions.” “Google took reasonable steps to preserve relevant documents.” “Plaintiffs were not prejudiced.” “Google did not act with an ‘intent to deprive.’” “No additional discovery is required or appropriate.”
United States’ Reply in Support of Its Motion for Sanctions Against Google. “Motion for sanctions is timely.” “Google did not disclose its chat destruction policy until January 2023.” “Google’s instruction to its employees to turn ‘history on’ is not reasonable” because “delegating its preservation obligations to employees was unreasonable” and “auto-deletion was unreasonable.” “The United States was prejudiced.”
“On the present record, the court cannot make a finding that Google acted ‘with the intent to deprive’ Plaintiffs of the ‘use’ of certain chats ‘in the litigation.’ Nor can it determine whether Google ‘failed to take reasonable steps to preserve’ such information.”
Ordered Google to produce for in camera review all litigation hold and reminder memoranda. Ordered Google to produce declarations from 20 custodians to be selected by the United States as to their practices in preserving chats, and what communications they held with chat history turned off.
Plaintiff’s Proposed Conclusions of Law at heading “Google’s Systematic Destruction Of Unfavorable Evidence Warrants Sanctions Under Rule 37(e).” “A party fails to take reasonable steps to preserve ESI when it (1) adopts a document destruction system that erases chats from production in litigations and investigations and then (2) continues to automatically delete the electronic communications of employees involved with the subject matter of a lawsuit and gives its employees ‘carte blanche to make his or her own call about what might be relevant in [a] complex antitrust case and whether a Chat communication should be preserved.’” (citing Google Play Store Antitrust Litigation)
As to preservation: “Google employees interchangeably refer to ‘history off’ chats as ‘off the record’ chats. Google permanently deletes all ‘off the record’ communications after 24 hours if both users in a one-on-one chat have their retention history set to ‘off,’ or if history is set to ‘off’ in a group chat.” “In September 2008, Google changed the default retention setting for many chats to ‘history off’.” Google’s Kent Walker said this would “help avoid inadvertent retention of instant messages.” “Google employees at all levels of responsibility—from the CEO to vice presidents to product managers—use ‘off the record’ chats for business purposes.” Lists specific purposes for which SVP Prabhakar Raghavan, SVP Jonathan Rosenberg, and VP Kolotouros used “history off” chats. “Google employees intentionally took chats to ‘history off’ to avoid preserving them.”
As to defaults: “Google has the technical capability to override default retention rules and set legal holds for all employees’ chats.” “Seven days [after] the United States informed Google that it intended to move for spoliation sanctions … Google changed its chat default settings and began to default chats to ‘history on’ for individuals on legal hold.”
As to improper claims of privilege: “Google trains its employees to shield emails and other documents from review and production in investigations and litigation.” “Google has long trained its employees to include attorneys on ‘any written communication regarding RevShare and MADA.’” “Google employees follow their training and include attorneys on ‘any written communication regarding revshare and MADA,’ even when not requesting legal advice.” “Google’s attempts to shield discovery include the company’s CEO. Mr. Pichai testified that he sometimes copied Chief Legal Officer Kent Walker on emails and asked for legal advice when he was not ‘really seeking legal advice, but … seeking confidentiality for the document’” and quoting his remarks: “There have been occasions where I’ve just marked [emails] privileged to indicate it’s confidential.” “After multiple rounds of re-review of ‘silent attorney’ emails, Google abandoned privilege on 12% (26 of 210 documents) of the random sample the Court requested for review in chambers, when it was clear it would be held accountable.”
As to employee use of terminology: “Google has cautioned its employees since at least 2003 to be careful about what they put in writing because it might be discoverable, and employees heed that caution.” (Referring to Antitrust Basics for Search Team.)
As to “Google’s long-time practice (since 2008) of deleting chat messages among Google employees after 24 hours”: “This failure to retain chats continued even after Google received the document hold notice at the start of the investigative phase of this case.”
As to Google’s “flagrant misuse of the attorney-client privilege”: Google “trained its employees to add its in-house lawyers on ‘any written communication regarding Rev Share [RSA] and MADA’” which, the Court says, led Google to initially withhold tens of thousands of records on the grounds of privilege, only to later deem them not privileged.
Says the Court need not make a finding of intent in Google’s failure to preserve these documents or its incorrectly marking them as privileged, because intent is not an element of the underlying antitrust claims. “Still, the court is taken aback by the lengths to which Google goes to avoid creating a paper trail for regulators and litigants. It is no wonder then that this case has lacked the kind of nakedly anticompetitive communications seen in Microsoft and other Section 2 cases.” After quoting other companies’ improper statements indicating antitrust violations, the Court continues: “Google clearly took to heart the lessons from these cases. It trained its employees, rather effectively, not to create ‘bad’ evidence.”
As to remedy: “On the request for sanctions, the court declines to impose them. Not because Google’s failure to preserve chat messages might not warrant them. But because the sanctions Plaintiffs request do not move the needle on the court’s assessment of Google’s liability.” “The court’s decision not to sanction Google should not be understood as condoning Google’s failure to preserve chat evidence. Any company that puts the onus on its employees to identify and preserve relevant evidence does so at its own peril. Google avoided sanctions in this case. It may not be so lucky in the next one.”
Filed August 13, 2020. First proceedings as to discovery violations: October 13, 2022.
Case allegation: Google acquired a monopoly in Android in-app payments, and Google unlawfully maintains a monopoly in Android mobile app distribution and payments. Complaint.
Case disposition: Jury ruled in Epic’s favor. Remedy on appeal to Ninth Circuit.
On the scope of deleted documents: “Google has destroyed—irretrievably—an unknown but undoubtedly significant number of communications by its employees about relevant business conversations, including on topics at the core of this litigation. Google permanently deletes Google Chats1 every 24 hours—and did so even after this litigation commenced, after Plaintiffs repeatedly inquired about why those chats were missing from Google’s productions, and after Plaintiffs submitted a proffer on this exact issue at the Court’s direction.”
On autodeletion: “Disabling an autodeletion function is universally understood to be one of the most basic and simple functions a party must do to preserve [Electronically Stored Information]” (quoting and citing DR Distribs). “It is difficult to imagine a litigant better situated to prevent automatic deletion on its own platforms than Google. When Google, whose stated mission is to ‘organize the world’s information and make it accessible,’ irretrievably destroys information despite multiple warnings, its conduct is intentional.”
Google’s Opposition to Motion for Sanctions. “Google took reasonable steps to preserve relevant ESI. … Rule 37(e) ‘does not call for perfection’.” “Plaintiffs do not show they suffered any prejudice. … Plaintiffs fail to explain why any unique evidence regarding their claims would be found in chats rather than in the massive corpus of contracts, emails, presentations, strategy documents, and transactional data produced by Google.”
Judge Donato on Google’s failing to preserve chats: “I think there’s little doubt on the evidence that we’ve heard so far that Chat, Google’s Chat function could, in fact, have contained evidence relevant … to this case. … Google did not systematically preserve those chats but, instead, left the preservation of chats to the discretion of each individual who received a hold notice. … Google never monitored the chats to see if relevant evidence was possibly being lost. … I’m concerned about all this for a variety of reasons [including] at our very first case management conference in October of 2020, Docket Number 45, Google represented to me that it had taken all appropriate steps to preserve all evidence relevant to the issues reasonably evident in this action. I’m finding that representation to the Court to be hard to square with what appears to have been failure to preserve the chats. … [I]f Google didn’t intend to preserve the chats, they should have told me about that in October of 2020.”
On remedy: “I’m not going to let Google get away with this is. There is going to be a substantial trial-related penalty”
On deletions generally: “Google’s argument that its efforts were reasonable is irreconcilable with the systematic and avoidable destruction of relevant Chats as well as its continued failure to explain why it did not suspend automatic deletion, including after being expressly put on notice.”
On prejudice: “Google’s contention that Plaintiffs have not suffered prejudice is refuted by evidence showing that Chats are just as substantive as (and often more candid than) email.”
On intent: “Google’s argument that it lacked the requisite intent ignores the facts that Google still, to this day, continues the wholesale destruction of Chats, that Google withheld information about the company’s destruction of Chats for months, and that Google’s custodians intentionally divert sensitive conversations to Chat to avoid discovery.” “Google employees intentionally divert sensitive conversations to ‘history off’ Chats, and chide others for honesty in ‘history on’ Chats.” “If Google truly believed that the wholesale destruction of all communications on one of the two communications platforms its employees routinely use was reasonable, it could have raised this position with Plaintiffs. It did not.” “Google’s conduct has the purpose of providing its employees a place to communicate free from discovery in litigation.”
Partial transcript of January 31, 2023 hearing. Judge Donato: “It’s plain as day to any objectively reasonable lawyer, any objectively reasonable lawyer, that Chat is going to contain possibly relevant evidence.”
Plaintiffs’ Supplemental Brief on Google’s Chat Production. “Google employees, including those in leadership roles, routinely opted to move from history-on rooms to history-off Chats to hold sensitive conversations, even though they knew they were subject to legal holds … even when discussing topics they knew were covered by the litigation holds in order to avoid leaving a record that could be produced in litigation..” Provides specific examples of substantive discussions in chat.
As to the reason why Google employees use chat, quoting from a preserved message: “Historically (ha) [Google employees] have history off so that [they] can speak (more) freely.” “[H]istory is a liability.” “Dont editorialize/comment in this group chat because it is long-lived.”
When employees realized history was on, they joked about turning it off: “heeeey . . . also just realized our history is [on] . . . can we turn it off? haha.”
As to discovery violations by Google CEO Sundar Pichai: “In one Chat, Mr. Pichai began discussing a substantive topic, and then immediately wrote: “also can we change the setting of this group to history off. Then, nine seconds later, Mr. Pichai apparently attempted (unsuccessfully) to delete this incriminating message. When asked under oath about the attempted deletion of the message, Mr. Pichai had no explanation, testifying ‘I definitely don’t know’ and ‘I don’t recall.'” (citing Pichai deposition transcript)
Quotes from specific employees evading document retention obligations:
Bill Richardson: “Historically (ha) we have history off so that we can speak (more) freely.”
Margaret Lam and Ethan Young: “I talk about RSA related things all day and I don’t have history on for all my chats :)” “we cannot delete it. I am also on multiple legal hold” “Ok maybe I take you off this convo”
Margaret Lam: “would it be too much to ask you to turn history off?” “lots of sensitivity with legal these days :)”
Margaret Lam and Shadia Walsh: “also just realized our history is [on]. can we turn it off? haha” “yes let’s turn it off”
Ambarish Kenghe: “Folks, *Please do consider if we nee to start a HISTORY OFF chat for this?* Threaded chats you can’t turn off history”
Talia Fernandes and Romin Malkan: “Since this is a sensitive discussion, I’m going to move it to a smaller room” “Group chat.. with the history off ;)”
Lyra Schramm: “should we have history off for this?”
Santiago Scully: “if super sensitive you need to use a GVC because they could look at your recent ping history and that could go into court”
Divya Chandra to Otto Jan: “I am on legal hold.” “Prefer to keep chat history off.” “i’ll turn off” [chat ends]
Edvill@, Sherle@, and Tris Warkentin: “quick aside – do we want history on?” “NO” “History is on. I suggest everyone leave the room and create a new one with history off. I am happy to punt everyone out”
Cdimon@: “please do not share sensitive information here where possible. Rather, you can flag documents, email threads, etc. for
attention. Until we fix the room architecture, content here is searchable/discoverable within the corp.”
Marcel Folaron: “We can’t turn history on due to potential sensitive information being shared”
Nentl@ and Thao Nguyen: “I’d imagine history is intentionally off” “Yes, history is intentionally turned off for all our war rooms.”
Brandon Barbello and Arpit Midha: “history is a liability” “the more we chat the more threads we need and the more history on gets dangerous”
Stephan Somogyi: ” if we create a new room from scratch we can disable history. We should find a way to do that rather than continuing in perma-history mode”
Tian Lim: “not sure why history is on for our chat, but can you turn it off”
Tian Lim: “hey history is on in this chat, needs to be off”
“Google trains employees to ‘communicate with care’.” (Training materials.) “[I]nternal communications actively expressed concerns about the possibility of disclosure in litigation and the risks of preserving Chats” (quoting seven specific employee discussions on this subject, e.g. “should we have history off for this?”). Employees specifically sought to evade retention obligations: “please do not share sensitive information here where possible . . . Until we fix the room architecture, content here is searchable/discoverable.”
On efficacy of Google’s approach to production and alternatives: “Google has the technical ability to set Chat history to ‘on’ as the default for all employees who are subject to a legal hold, but it chooses not to.” “Google did not check to see if custodians were actually preserving relevant Chats as directed by the hold notice, and did nothing in the way of auditing or monitoring Chat preservation.” “Overall, the record demonstrates that Google employees who received a litigation hold in this case were unable or unwilling to follow the Chat preservation instructions, and sometimes disregarded the instructions altogether.” Quotes a two-page chat between Google employees, which one recognizes as requiring preservation, to which the other says he will “take you off” the discussion rather than proceed with preservation. In another quoted chat, one employee said he was “on legal hold” but nonetheless “prefer[red] to keep chat history off”.
On scope and intent: Says Google “fell strikingly short” as to preservation, calls Google’s tactic “troubling” and a “worrisome” “substantial problem”, and says Google “did not reveal [its practices] with candor or directness to the Court or … plaintiffs.” Criticizes Google’s efforts to “downplay the problem” including its “dismissive attitude ill tuned to the gravity of its conduct.” Criticizes Google’s false claim that it was unable to change default chat history settings for individual employees, which the court says was “not truthful”. Concludes that “Google did not take reasonable steps to preserve electronically stored information that should have been preserved.” As to “intentionality,” concludes “that Google intended to subvert the discovery process, and that Chat evidence was “lost with the intent to prevent its use in litigation” and “with the intent to deprive another party of the information’s use in the litigation.” Rejects Google’s arguments about impact of the failure to preserve.
On remedy: “The determination of an appropriate non-monetary sanction requires further proceedings. The Court fully appreciates plaintiffs’ dilemma of trying to prove the contents of what Google has deleted. Even so, the principle of proportionality demands that the remedy fit the wrong, and the Court would like to see the state of play of the evidence at the end of fact discovery. At that time, plaintiffs will be better positioned to tell the Court what might have been lost in the Chat communications.”
On monetary sanctions: “[I]t is entirely appropriate for Google to cover plaintiffs’ reasonable attorneys’ fees and costs in bringing the Rule 37 motion, including the joint statement that preceded the motion and the evidentiary hearing and related events.”
On retention: “The record contains example after example of Google employees beginning to discuss topics highly relevant to this litigation and then quickly agreeing to turn history off to trigger automatic deletion and shield further discussion from discovery. … These interrupted Chats are the tip of the iceberg and are powerful evidence of key information—which by any reasonable inference is information that Google thought would be harmful to its legal position if disclosed—being deliberately and permanently destroyed, and thus hidden from Plaintiffs and the Court.” Says the destroyed information was “the most candid and unsanitized discussions regarding Google’s anticompetitive conduct.” Quotes additional specific examples of employees turning off chat to avoid document preservation, including Google CEO Sundar Pichai.
On privilege Calls out “fake privilege” in which Google “encouraged” employees “to copy… counsel to apply attorney-client privilege” although not genuinely seeking legal advice.
On remedy: Seeks a permissive adverse inference, directing the jury that it “may” infer that Google destroyed evidence which would have been harmful to Google and helpful to Plaintiffs.
Google’s Opposition to Plaintiffs’ Proposed Remedy. Criticizes Plaintiffs’ proposal as “severe.” “Plaintiffs’ submission does not show that Google’s post-August 13, 2020 chat preservation practices deprived them of evidence that would have strengthened their case.” “Plaintiffs offer nothing more than rank speculation that any missing chats would have been relevant—let alone helpful—to their case.” “The vast majority of the conduct discussed in Plaintiffs’ motion took place before this lawsuit was filed—in many cases years before this lawsuit was filed—and therefore any chats on these topics would have been permissibly deleted pursuant to Google’s document retention policy long before Google’s preservation obligations arose.” “Plaintiffs say that [certain] chats would have revealed Google’s subjective motivation for the challenged conduct, but the inquiry in this antitrust case focuses on effect, not intent.”
Plaintiffs’ Reply ISO Proposed Remedy. “The time has come for Google to bear the consequences of its longstanding, deliberate policy of instructing its employees to conduct their most sensitive business communications in ‘history off’ Chats and then destroying those Chats despite pending litigation to which they were relevant, including this case and related investigations and regulatory actions.” “Plaintiffs’ requested remedy is appropriately tailored to attempt to ameliorate the prejudice and harm resulting from Google’s calculated choice to evade discovery obligations and destroy evidence.” “Plaintiffs have shown—as far as is possible without the benefit of the documents Google destroyed—that the thousands upon thousands of deleted Chats contained probative evidence that would have supported Plaintiffs’ case.” “Google’s plea for ‘lesser measures’ fails because Google has not identified any ‘lesser measures’ that would be sufficient to redress Plaintiffs’ loss.”
Remedy in pretrial order. Orders a permissive adverse inference jury instruction, consistent with Plaintiffs’ proposal.
Evidentiary hearing as to discovery violations summarized in Epic’s Opposition to Google’s Renewed Motion for Judgment as a Matter of Law under Rule 50(B) or for a New Trial under Rule 59. “Trial testimony from Google witnesses … confirmed the destruction of hundreds of thousands of Chats.” Judge called Kent Walker’s testimony “evasive” and “materially inconsistent with testimony given by Google’s witnesses”, saying his testimony “did not do anything to assuage [the Court’s concerns.” Judge remarked that “a mandatory adverse inference instruction would be amply warranted.” Judge continued: “this presents the most serious and disturbing evidence I have ever seen in my decade on the bench with respect to a party intentionally suppressing potentially relevant evidence in litigation” and remarked on “rampant and systemic culture of evidence suppression at Google.” Judge said he intended to conduct his own independent investigation into “who is responsible within Google for tolerating this culture of suppression.”
As to abuse of privilege designations: “[M]ore evidence emerged at trial of a frankly astonishing abuse of the attorney-client privilege designation to suppress discovery. CEO Pichai testified that there were occasions when he ‘marked e-mails privileged, not because [he was] seeking legal advice but just to indicate that they were confidential,’ as he put it. He knew this was a misuse of the privilege. Emily Garber, a Google in-house attorney, testified that there was a practice at Google of ‘loop[ing] in’ a lawyer based on a ‘misapprehension about the rules of privilege,’ and that Google employees ‘believed that including [an in-house lawyer] would make it more likely that the email would be considered privileged.’ Garber called this ‘fake privilege,’ a practice that she appears to have found amusing rather than something a lawyer should have put an immediate and full stop to. On this record, there was no error in the Court’s evidentiary ruling that Epic could ‘present fake privilege’ and make arguments to the jury about it.”
As to adverse inference: “The Court determined after an evidentiary hearing held before trial that Google had willfully failed to preserve relevant Google Chat communications, and allowed employees at all levels to hide material evidence. The evidence presented at trial added more fuel to this fire. As discussed, Google in-house attorney Garber testified about the company practice of asserting a fake privilege to shield documents and communications from discovery. Other witnesses also amplified the seriousness and pervasiveness of Google’s preservation abuse. For example, Google employee Margaret Lam, who worked on RSA issues, said in a Chat message that she didn’t have a specific document because ‘competition legal might not want us to have a doc like that at all :).’ She was a party to other Chats where, in a discussion about MADA, she asked to turn history off because of ‘legal sensitivity’; she requested to turn history off in a different conversation about RSAs, so there would be no ‘trail of us talking about waivers, etc.’” “Overall, there was an abundance of pretrial and trial evidence demonstrating ‘an ingrained systemic culture of suppression of relevant evidence within Google.’”
As to the Court’s evidentiary hearing to evaluate a mandatory adverse inference about Google’s suppression of evidence: “The results of this hearing were disappointing. Google’s chief legal officer, Kent Walker, was the main witness. Despite the seriousness of these issues, and the likelihood that they could affect other litigation matters where Google is a party, Walker showed little awareness of the problems and had not investigated them in any way. Much of his testimony was in direct opposition to the facts established at the prior Google Chat hearing. Overall, Walker did nothing to assuage the Court’s concerns.” “Even so, the Court took the conservative approach of permitting the jury to make an adverse inference rather than requiring it to.” “Google’s complaints about the inference instruction are wholly misdirected. It has not provided anything close to a good reason to conclude otherwise.”
Three separate judges recently remarked on Google’s failure to preserve and produce documents relevant to antitrust claims against Google. (More here.) In response, critics asked the State Bar of California to investigate Google General Counsel Kent Walker for violating the California Professional Code of Conduct in counseling Google to destroy records to multiple ongoing lawsuits, including his 2008 memo instructing employees to “avoid inadvertent retention” of communications that might be “used against” Google in litigation.
From the timeline, one might think Google’s document preservation practices were perfect until the recent matters. Note memo written in2008 versus litigation in 2023-2024 questioning document retention. If there were no discovery grievances during that fifteen-year period, maybe this is the first time Google failed to conduct itself properly during discovery – or at least the first time anyone figured out the problem and called Google out on it. If so, maybe this is genuinely some kind of mistake, and maybe the sanction on Google should be correspondingly reduced.
Not so. I have been following Google litigation for longer than most. When I read the recent briefs and decisions about Google’s failure to preserve documents, I immediately thought of a different episode, a decade and a half ago, when Google failed to preserve documents relating to YouTube despite knowing about likely litigation.
Google’s failure to preserve documents relating to copyright infringement at YouTube
When Google considered acquiring YouTube, copyright concerns loomed large. Analyzing a sample of videos from YouTube, Credit Suisse bankers found that more than 60% of YouTube video views were “premium” (their euphemism for copyright), and only 10% of those were licensed. In this period, YouTube faced competition from, among others, Google Video—which took genuine steps to protect copyright. Seeing YouTube traffic soar while they struggled, Google Video staff were unsparing in their criticism of YouTube’s approach to copyright, calling YouTube, “a rogue enabler of content theft” “completely sustained by pirated content” “trafficking mostly illegal content”. (See also Google’s slides about copyright risks and rights-holder criticism.) Concerned about a “precedent-setting lawsuit” about copyright, Google held back a 12.5% escrow from the YouTube acquisition price to cover possible copyright liability. With Google’s own staff explicitly criticizing YouTube’s approach to copyright, and Google’s term sheet discussing copyright risks, copyright litigation was not just foreseeable; it was actually foreseen, then measured and priced.
Under longstanding law, when litigation is reasonably foreseeable, a party is obliged to preserve documents for use as evidence. (See e.g. Silvestri v. General Motors, 271 F.3d 583, 590.) From the start, copyright infringement at YouTube was far beyond that modest standard. So from the first moment Google began to consider acquiring YouTube, Google should have preserved all relevant documents. Certainly when the acquisition was completed, with copyright concerns still looming large and threats from rights-holders ongoing, Google was obliged to preserve.
Rather than preserve documents relating to copyright infringement at YouTube, Google did much the opposite. The most brazen missing emails are those sent and received by then-CEO Eric Schmidt. In a May 6, 2009 deposition, Schmidt indicated having about 30 computers (page 7 line 10) but configuring them “to not retain my e-mails unless asked specifically” (17:9-10). Asked whether he deleted them manually versus through some sort of automation, Schmidt said “the answer would vary” (18:17-18). He said he would “delete or otherwise cause the emails that I had read to go way as quickly as possible” (18:24 to 19:2). Asked whether he began to preserve documents after a copyright lawsuit was filed alleging widespread infringement at YouTube, Schmidt said “I did change my practice after this lawsuit was filed and I was notified” but refused to reveal details which he indicated were attorney-client privileged. Despite the possible change to Schmidt’s retention practice after the Viacom case was filed, searching his email for responsive documents yielded only 19. (Hohengarten declaration ¶266) Google’s acquisition of YouTube was its largest transaction to date. It is inconceivable that the CEO of Google would have just 19 emails pertaining to its largest acquisition. By his own admission, Schmidt “deleted or otherwise cause[d]” to be deleted the huge number of otherwise-responsive emails. Thousands? Tens of thousands? Meanwhile, if he changed his document retention practice after the lawsuit was filed, why aren’t there more documents from that period? He wouldn’t say, and it seems the world will never know.
(Incidentally, even Page’s deposition transcript almost didn’t see the light of day. Initially, this deposition was filed under seal in Viacom v. Google litigation as Hohengarten declaration part 11 (docket #222) attachment #20, redacted in full at Google’s request. See also docket #247, ordering that redaction. But in rechecking the docket incidental to this article, I found later docket #324, which provides the transcript. Last month I uploaded these files to Courtlistener for public archival and review. Page’s deposition is Attachments 5, 6, and 7. Until I uploaded Page’s deposition transcript to Courtlistener, these files lingered in PACER – unindexable by web search, available only for those who knew exactly where to look, knew how to log in, and were willing to pay per-page access fees.)
The memory of YouTube co-founder Chad Hurley was equally poor, but newly revealed in Attachments 2-4 in the same docket #324. Hurley had no difficulty recalling most aspects of product strategy, negotiation strategy, and distribution strategy. However he was unable to recall multiple subjects that were sensitive in light of the litigation: the basis of Google’s valuation of YouTube (part 1 pages 29-32), entire movies uploaded to YouTube (part 2 pages 12-16), copyright enforcement policies (part 2 pages 19-20 and 26-30), and why YouTube removed ads from Watch Pages (part 2 pages 23-24)—Hurley said he couldn’t recall.
Separately, Viacom calls out Google’s failure to produce relevant documents within its possession. For example, on March 22, 2006, YouTube founder Jawed Karim presented to the YouTube board of directors:
As of today episodes and clips of the following well-known shows can still be found: Family Guy, South Park, MTV Cribs, Daily Show, Reno 911, Dave Chapelle. This content is an easy target for critics who claim that copyrighted content is entirely responsible for YouTube’s popularity. Although YouTube is not legally required to monitor content (as we have explained in the press) and complies with DMCA takedown requests, we would benefit from preemptively removing content that is blatantly illegal and likely to attract criticism.
Having acquired YouTube, Google should have received the materials previously presented to YouTube’s board. Yet Google failed to produce this document to Viacom in litigation. Viacom only received it when Karim, to his credit, produced it after he left YouTube.
Rereading Google’s deficient discovery in the Viacom’s matter, in conjunction with 2023-2024 proceedings about Google discovery violations, to me the picture became increasingly clear. Google’s decision to evade discovery obligations isn’t a new problem, and it isn’t really a change. Rather, this problem has been lingering for years, and has surely harmed scores of other litigants—whose ability to prove their cases against Google was stymied by Google falling short of both the productions and the candor required by court rules. For broader thoughts and more on the other discovery disputes, see Revisiting litigation alleging Google discovery violations.